

Truefoundry
Web LLaMA Llama-2 7B RTX 3060 GTX 1660 2060 AMD 5700 XT RTX 3050 AMD 6900 XT RTX 2060 12GB 3060 12GB 3080 A2000. Web A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. Web Some differences between the two models include Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters Llama 2 was trained on 40 more data. Web Get started developing applications for WindowsPC with the official ONNX Llama 2 repo here and ONNX runtime here Note that to use the ONNX Llama 2 repo you will need to submit a request to. Web The Llama 2 family includes the following model sizes The Llama 2 LLMs are also based on Googles Transformer architecture but have some..
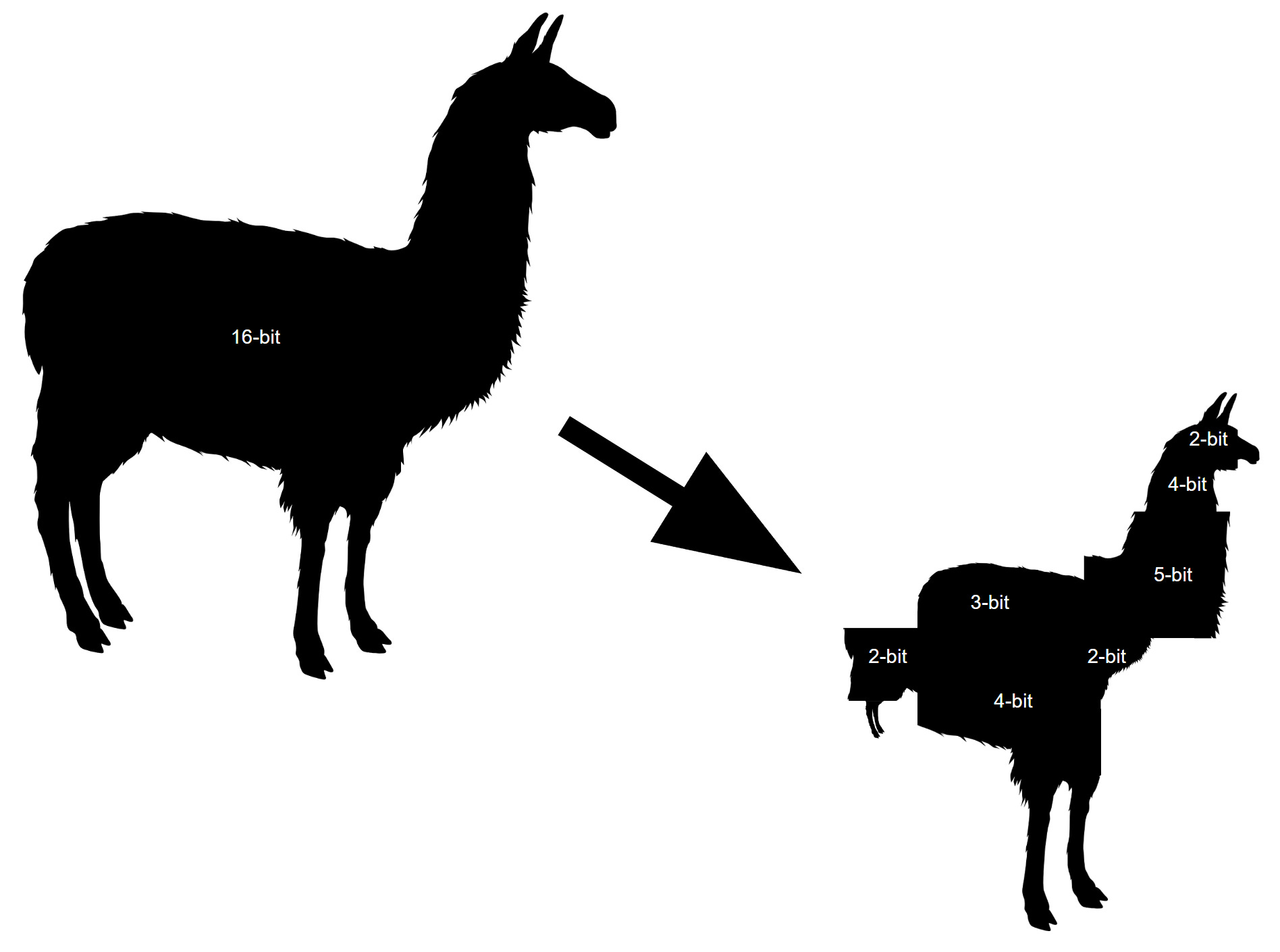
This release includes model weights and starting code for pretrained and fine-tuned Llama language models ranging from 7B to 70B parameters This repository is intended as a minimal example to load Llama 2 models. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration in Hugging Face. The llama-recipes repository is a companion to the Llama 2 model The goal of this repository is to provide examples to quickly get started with fine-tuning for domain adaptation and how to run inference for the. The LLaMA 2 model incorporates a variation of the concept of Multi-Query Attention MQA proposed by Shazeer 2019 a refinement of the Multi-Head Attention MHA algorithm MQA enhances the efficiency of attention. Llama 2 is a collection of pretrained and fine-tuned generative text models To learn more about Llama 2 review the Llama 2 model card What Is The Structure Of Llama 2 Llama 2 model consists of a stack of decoder layers..
The Kaitchup Substack
An abstraction to conveniently generate chat templates for Llama2 and get back inputsoutputs cleanly The Llama2 models follow a specific template when prompting it. WEB Whats the prompt template best practice for prompting the Llama 2 chat models Note that this only applies to the llama 2 chat models The base models have no prompt structure. WEB We have collaborated with Kaggle to fully integrate Llama 2 offering pre-trained chat and CodeLlama in various sizes To download Llama 2 model artifacts from Kaggle you must first request a. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters This is the repository for the 13B fine-tuned. WEB In this post were going to cover everything Ive learned while exploring Llama 2 including how to format chat prompts when to use which Llama variant when to use ChatGPT..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Open source free for research and commercial use Were unlocking the power of these large language models Our latest version of Llama Llama 2 is now accessible to individuals. Llama 2 a product of Meta represents the latest advancement in open-source large language models LLMs It has been trained on a massive dataset of 2. ..




Komentar